决策树
1. 基础知识
条件熵:
互信息:
有些将互信息定义为:

2. 决策树
- 决策树:自顶向下的递归方法,以信息熵为度量为度量,构造一颗熵值下降最快的树;叶子节点的熵值是0;
- 决策树:一种树型结构,其中每个内部节点表示一个属性上的测试,一个分支代表一个测试输出,每个叶节点表示一种类别
* 算法
- ID3
- C4.5
- CART
2.1 信息增益

经验熵,经验条件熵:通过样本计算后得到的熵
g(D,A):表示特征A对训练数据集D的信息增益;
=> 集合D的经验熵H(D)与特征A给定下D的经验条件熵H(D|A)的差值
=> 也可以理解为一种互信息的写法
* 基本符号

* 信息增益计算

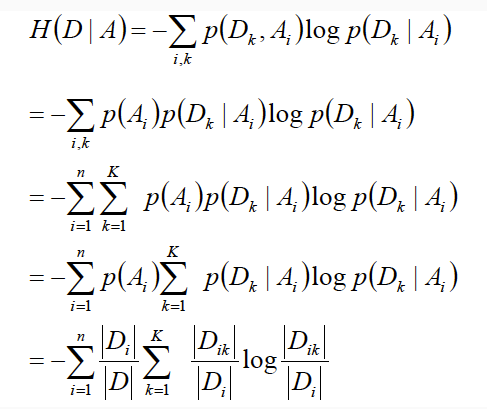
* 为什么用信息增益来选择特征
设信息熵是:
信息增益是熵的减少量
信息增益越大,表明属性对样本的熵减少的能力越强,使得数据由不确定性变为确定性的能力越强;即“纯度”提升越大;
- 熵:随机变量的不确定性
- 条件熵:在一定条件下,随机变量的不确定性
信息增益:熵-条件熵(减法):一定条件下,信息不确定性减少的程度
例子:
通俗地讲,X(明天下雨)是一个随机变量,X的熵可以算出来, Y(明天阴天)也是随机变量,在阴天情况下下雨的信息熵我们如果也知道的话(此处需要知道其联合概率分布或是通过数据估计)即是条件熵。
两者相减就是信息增益!原来明天下雨例如信息熵是2,条件熵是0.01(因为如果是阴天就下雨的概率很大,信息就少了),这样相减后为1.99,在获得阴天这个信息后,下雨信息不确定性减少了1.99!是很多的!所以信息增益大!也就是说,阴天这个信息对下雨来说是很重要的!
所以在特征选择的时候常常用信息增益,如果IG(信息增益大)的话那么这个特征对于分类来说很关键~~ 决策树就是这样来找特征的!
* 信息增益率
* 基尼指数
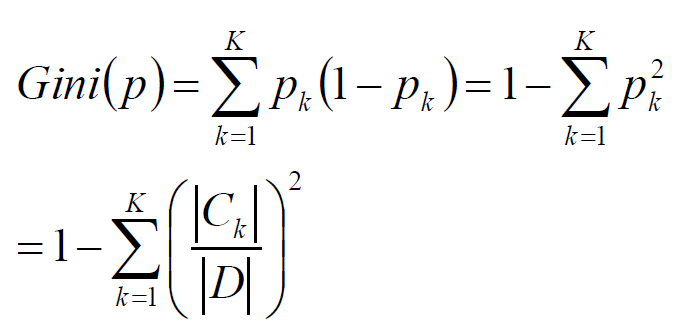
* 信息增益
2.2 信息增益,信息增益比,基尼指数
信息增益选择方法缺点:总是倾向于选择属性值多的属性;信息增益比改进;信息增益比衡量的是当前节点提供的信息量与它本身所含信息量之比,或说是特征提供信息的效率
基尼指数:Gini(D)表示集合D的不确定性,Gini(D,A)表示经过A=a分割后集合D的不确定性;基尼指数越大,样本的不确定性越大,类似熵
基尼指数:计算快


- 熵的一半和基尼指数可以近似的代替分类误差率