预处理
NiuTrans:小牛翻译 Mesos
1 对双语分别做预处理
1.1 中文预处理
* 分词(结巴分词)
* 时间,日期,网址的替换
1.2 英文的预处理
* 大写改小写
* 句子结尾句号,和单词分块
* 时间,日期,网址的替换
2. 词对齐
* 词对齐的任务:得到中英文短语的对应关系
* GIZA++ : IBMModel和HMM等
* 词对齐的任务:将两个文件合并
3. 抽取短语
- GIZA++词对齐后可以进行短语抽取 * 短语抽取是短语翻译表达的第一步,短语翻译表达是翻译系统解码器要使用的重要组件之一
* 短语抽取的本质
- 从含有词对齐信息的平行句对中抽取基于短语的统计机器翻译系统使用的翻译短语
* 一致性短语(定义)
* 抽取的短语需要和词对齐保持一致
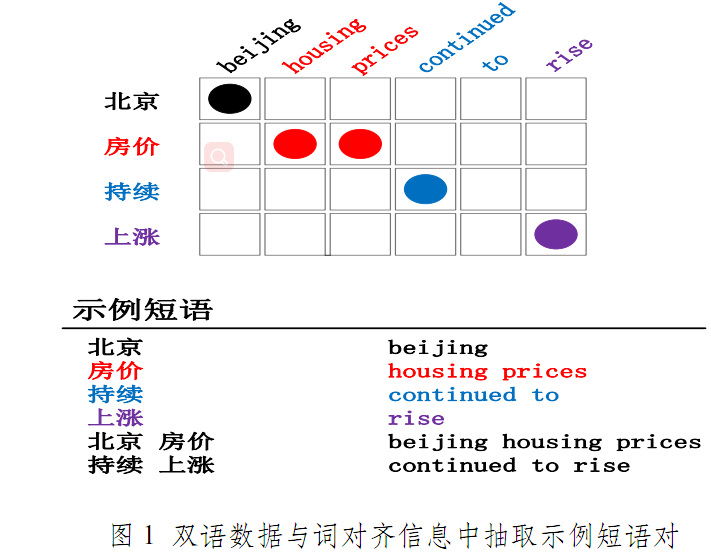
- 上述六条均于词对齐保持一致
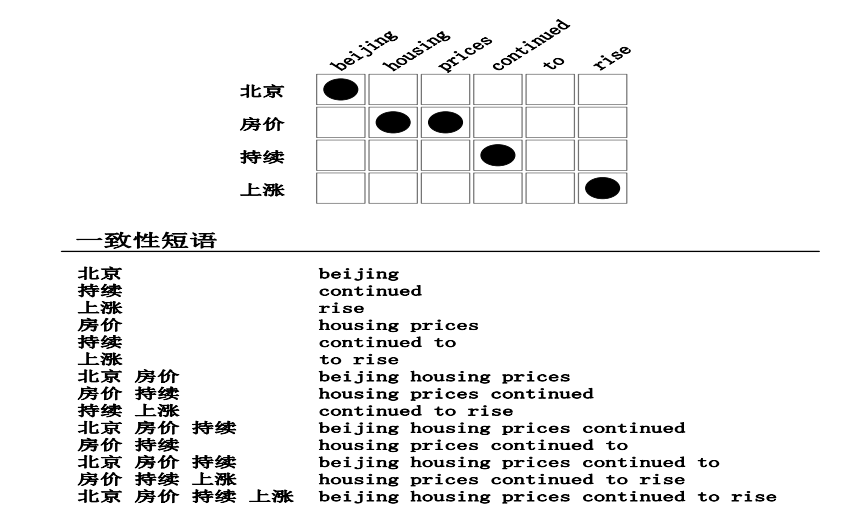
* 短语抽取算法(如何抽取一致性短语)
* 算法抽取后的结果
4 概率估计
* 短语翻译中的四个概率特征及计算方法
- 短语抽取后,获得给予短语系统使用的翻译短语对,概率估计的作用是对翻译短语对的正确性做合理的评估
* 短语对集合例子
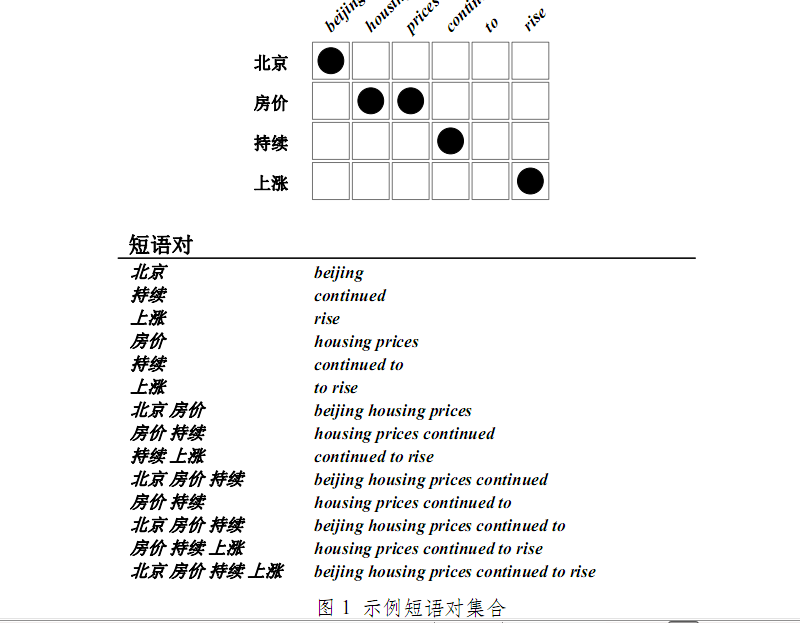
- 抽取14条与词对齐保持一致的短语对(概率估计在短语上进行)
* 需要计算四个部分
- 双向短语概率(正向:源语言-->目标语言;反向:目标语言-->源语言)
- 双向词汇化权重
- 出现稀疏性和不可靠性,通过将短语对分解成词的翻译,检查短语对的匹配程度,词汇化加权
* 双向短语
*词汇化加权:将源语言和目标语言分解为词汇,检查词汇间的匹配程度
- 原语言-->目标语言,词汇加权
- 目标语言-->源语言,词汇加权
5. 解码
计算最佳的翻译路径 结合语言模型和短语翻译概率得到解码

---