PLSA(概率潜语义分析)
通过添加主题的方式:解决:
- 一词多义:一个词被映射到多个主题
- 多次一义: 多个次被映射到某个主题
1. plsa的推导
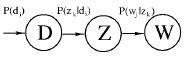
- D是文档;Z是主题;W是观察到的单词 *:单词出现在文档的概率
- :文档出现主题的概率
- :给定主题词出现单词的概率
=>
- 每个主题在所有词项上服从多项分布;每个文档在多有主题上服从多项分布;
=>文档生成过程:
- 以的概率选中文档
- 以的概率选中主题
- 以的概率产生一个单词
=>观察到的数据是:,即(文档,单词);主题是隐含变量
- 的联合分布是:
其中:,对应了两组多项分布,需要去估计参数;
2. PLSA使用EM算法估计参数
- 需要去估计参数的分布是:;
2.1 极大似然函数
- 其中: :表示在中出现的次数
- i:文本个数;j:单词个数
- K:主题的个数
=>
2.2 目标函数建模
已知: 观测数据,主题是隐含变量
目标函数:
未知变量:;
2.3 求解策略
- EM算法
- E步:假设和已知(初始化随机赋值) 求隐含变量的后验概率
- M步:最大化对数似然函数的期望:
=>期望:
=>期望最大化
2.4 最大期望的求解
求解Lagrange函数:
求驻点
2.5 最终求解表达式
- E-step:
- M-step: