人工神经网络
* 历史
http://www.cnblogs.com/subconscious/p/5058741.html?utm_source=tuicool&utm_medium=referral
- 神经网络是一种模拟人脑的神经网络以期能够实现类人工智能的机器学习技术
1. 前言
* 典型网络

* 神经网络的设计原则
- 设计一个神经网络时,输入层与输出层的节点数往往是固定的,中间层则可以自由指定;
- 神经网络结构图中的拓扑与箭头代表着预测过程时数据的流向,跟训练时的数据流有一定的区别;
- 结构图里的关键不是圆圈(代表“神经元”),而是连接线(代表“神经元”之间的连接)。每个连接线对应一个不同的权重(其值称为权值),这是需要训练得到的。
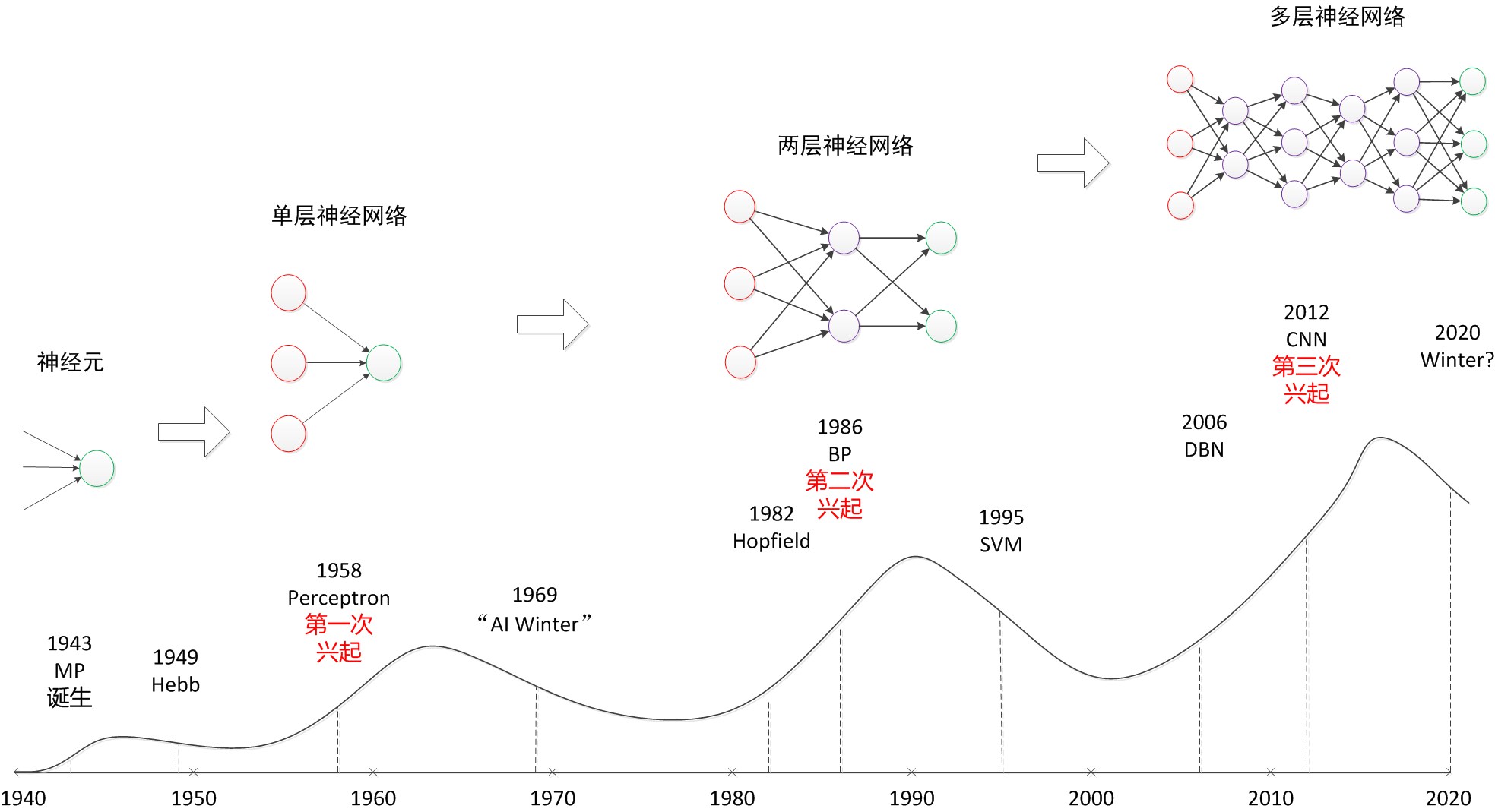
2. MP
1943年,心理学家McCulloch和数学家Pitts参考了生物神经元的结构,发表了抽象的神经元模型MP。在下文中,我们会具体介绍神经元模型。

* 神经元模型

连接是神经元中最重要的东西。每一个连接上都有一个权重。
一个神经网络的训练算法就是让权重的值调整到最佳,以使得整个网络的预测效果最好。
* 神经元的计算

- 可见z是在输入和权值的线性加权和叠加了一个函数g的值。在MP模型里,函数g是sgn函数,也就是取符号函数。这个函数当输入大于0时,输出1,否则输出0。
* 神经元计算的扩展
首先将sum函数与sgn函数合并到一个圆圈里,代表神经元的内部计算。其次,把输入a与输出z写到连接线的左上方,便于后面画复杂的网络。最后说明,一个神经元可以引出多个代表输出的有向箭头,但值都是一样的。
神经元可以看作一个计算与存储单元。计算是神经元对其的输入进行计算功能。存储是神经元会暂存计算结果,并传递到下一层。

2. Hebb学习率
- MP模型中,权重的值都是预先设置的,因此不能学习。
- 1949年心理学家Hebb提出了Hebb学习率,认为人脑神经细胞的突触(也就是连接)上的强度上可以变化的。于是计算科学家们开始考虑用调整权值的方法来让机器学习。
3. 感知器
- 1958年,计算科学家Rosenblatt提出了由两层神经元组成的神经网络。他给它起了一个名字--“感知器”(Perceptron)
- 感知器是当时首个可以学习的人工神经网络。Rosenblatt现场演示了其学习识别简单图像的过程,在当时的社会引起了轰动。
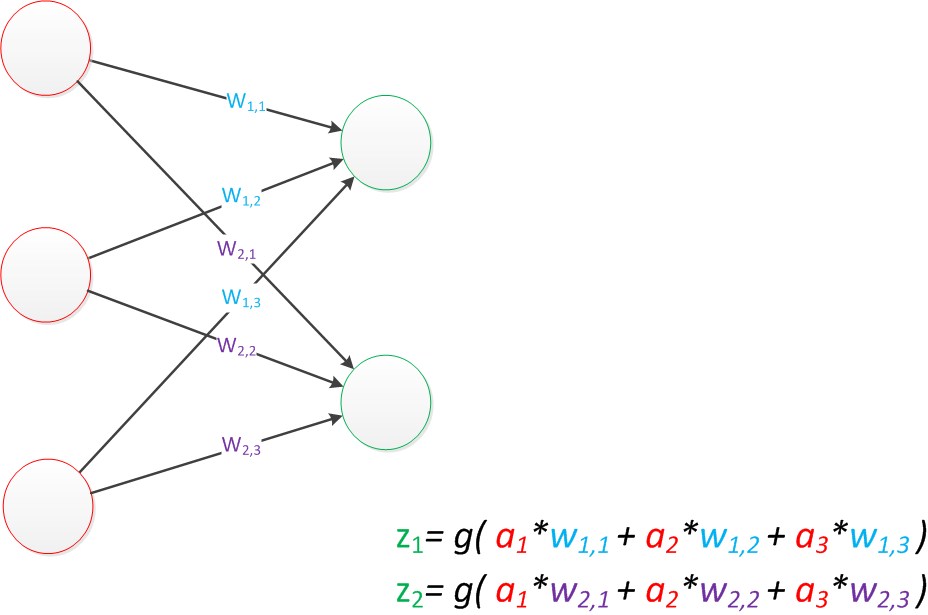
- 两个公式就是线性代数方程组。因此可以用矩阵乘法来表达这两个公式。
- 与神经元模型不同,感知器中的权值是通过训练得到的。因此,根据以前的知识我们知道,感知器类似一个逻辑回归模型,可以做线性分类任务。
* 影响
Minsky在1969年出版了一本叫《Perceptron》的书,里面用详细的数学证明了感知器的弱点,尤其是感知器对XOR(异或)这样的简单分类任务都无法解决。
Minsky认为,如果将计算层增加到两层,计算量则过大,而且没有有效的学习算法。所以,他认为研究更深层的网络是没有价值的。
* 这个时期又被称为“AI winter”。
4. 两层神经网络(多层感知器)
Minsky说过单层神经网络无法解决异或问题。但是当增加一个计算层以后,两层神经网络不仅可以解决异或问题,而且具有非常好的非线性分类效果。不过两层神经网络的计算是一个问题,没有一个较好的解法。
1986年,Rumelhar和Hinton等人提出了反向传播(Backpropagation,BP)算法,解决了两层神经网络所需要的复杂计算量问题,从而带动了业界使用两层神经网络研究的热潮。目前,大量的教授神经网络的教材,都是重点介绍两层(带一个隐藏层)神经网络的内容。

- 两层神经网络除了包含一个输入层,一个输出层以外,还增加了一个中间层。此时,中间层和输出层都是计算层。我们扩展上节的单层神经网络,在右边新加一个层次(只含有一个节点)。

* 与单层神经网络不同。理论证明,两层神经网络可以无限逼近任意连续函数。
多层的神经网络的本质就是复杂函数拟合
输入层的节点数需要与特征的维度匹配,输出层的节点数要与目标的维度匹配。而中间层的节点数,却是由设计者指定的。
* svm
- 90年代中期,由Vapnik等人发明的SVM(Support Vector Machines,支持向量机)算法诞生,很快就在若干个方面体现出了对比神经网络的优势:无需调参;高效;全局最优解。基于以上种种理由,SVM迅速打败了神经网络算法成为主流。
5 多层神经网络(深度学习)
- 2006年,Hinton在《Science》和相关期刊上发表了论文,首次提出了“深度信念网络”的概念。与传统的训练方式不同,“深度信念网络”有一个“预训练”(pre-training)的过程,这可以方便的让神经网络中的权值找到一个接近最优解的值,之后再使用“微调”(fine-tuning)技术来对整个网络进行优化训练。这两个技术的运用大幅度减少了训练多层神经网络的时间。他给多层神经网络相关的学习方法赋予了一个新名词--“深度学习”。
6 经验
在单层神经网络时,我们使用的激活函数是sgn函数。到了两层神经网络时,我们使用的最多的是sigmoid函数。而到了多层神经网络时,通过一系列的研究发现,ReLU函数在训练多层神经网络时,更容易收敛,并且预测性能更好