基于内容:物品表示

* 内容分析器
- 文档数据的处理
- 得到结构化的数据,存储在物品库中
* 信息学习器
收集用户的相关偏好数据特征,泛化这些数据,构建用户特征模型(机器学习)
通过历史数据构建用户兴趣特征
生成兴趣特征和无兴趣特征
* 过滤器
- 用户信息和物品信息匹配
- 计算相似度
- 生成潜在的兴趣物品名单
* 反馈
- 喜欢/不喜欢
- 评分
- 文本评论
* 算法流程
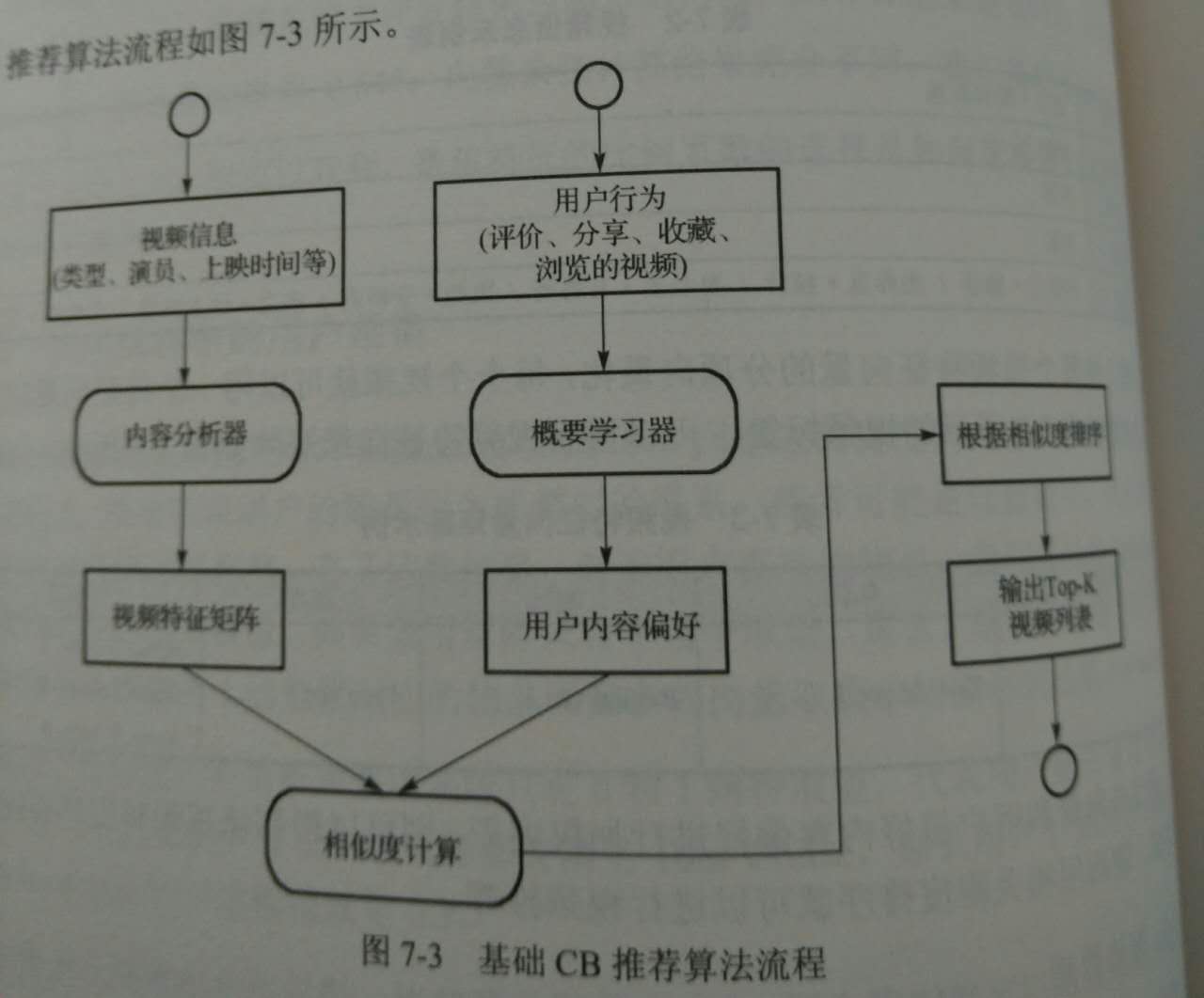
物品特征的表示
- 推荐给用户的物品可以表示为一系列的特征
- 例如:一部电影的特征:演员,导演,类型,主题等
用户特征的学习方法
- 学习一个队用户兴趣建模的函数
* 总结
基于内容推荐的步骤
- 对数据内容分析,得到物品的结构化描述
- 分析用户过去的评分或评论过的物品的,作为用户的训练样本
- 生成用户画像 a.可以是统计的结果(后面使用相似度计算) b.也可以是一个预测模型(后面使用分类预测计算)
- 新的物品到来,分析新物品的物品画像
- 利用用户画像构建的预测模型,预测是否应该推荐给用户U a.策略1:相似度计算 b.策略2:分类器做预测
- 进一步,预测模型可以计算出用户对新物品的兴趣度,进而排序
- 进一步,用户模型在变化,通过反馈更新用户画像(用户画像在这里就是预测模型)
- 反馈-学习,构成了用户画像的动态变化
基于内容推荐的算法
空间向量模型(最基础的CB方法)
用户信息和物品信息都被表示为带权重的词向量,使用余弦相似的计算用户对一个物品的兴趣度 例如:
- 物品画像表示为视频的属性(TF-IDF):(视频名字,导演,主演,....)
- 用户画像(喜欢或者不喜欢的电影类型):(视频名字,导演,主演,....)
- 计算相似度(余弦相似度)
内容相似度的检索
- 基于knn的最近邻的方法(基于空间向量模型)
- 选择出用户u喜欢的文档集合
- 在这些文档集合中,选择k个和新文档最相似的文档( 相似度使用余弦相似度计算)
- 注意区别和CF:cb的方法中是用文档和文档内容的相似度计算,而cf的方式是通过用户的打分来计算